O título deste post é enganador, porque devia ser apenas “Acelerar O”, já que vou apenas escrever sobre como há uns tempos, junto com um colega, tentamos melhorar a velocidade de escrita de um programa em C++. Peço já desculpa em adiantamento por qualquer erro ou falta de pormenor na narrativa, mas tudo isto já foi há uns tempos.
A ideia da coisa era simples: converter um formato binário para XML e vice-versa, sendo que os ficheiros em XML utilizavam de 2 a 8x o tamanho do binário original (o que, quando se tem binários na ordem dos GBs, é chato). Um dos requisitos era que um binário de 1GB demorasse no máximo 30s a converter para XML (o que necessita de um throughput de ~130MB/s, que é uma meta realista para um bom HDD).
Lá desenvolvemos o bixo e fizemos as primeiras medições depois de configurar as as otimizações do compilador (que era o SunStudio, já agora) … estava a demorar 90s, o triplo do que era suposto. Depois do profiling devido, descobrimos que o problema estava numa função bastante simples que fazia a conversão dos vários tipos de atributos do XML para string.
template<class T> string to_string(T attr_value) {
stringstream ss;
ss << T;
string str = ss.str();
(... some business logic ...)
return res;
}O primeiro passo foi evitar a construção de uma stringstream sempre que a função era invocada.
template<class T> string to_string(T attr_value) {
static stringstream ss;
ss.str("");
ss << T;
string str = ss.str();
(... some business logic ...)
return res;
}70s, melhor mas ainda mais do dobro do esperado. Entretanto percebemos que os templates davam uma machada grande na performance, e por isso começamos por tentar template specialization para os casos mais comuns:
template<> string to_string(const float & attr_value) {
sprintf(buf, "%g\0", sValue);
(... some business logic ...)
return buf;
}
template<class T> string to_string(T attr_value) {
static stringstream ss;
ss.str("");
ss << T;
string str = ss.str();
(... some business logic ...)
return res;
}Pouco mudou: 65s. Deixamos de usar templates e stringstreams para as conversões e passamos a ter uma função especializada para cada tipo de dados e além disso passamos as funções para inline, mesmo assim não baixou dos 60s.
A última coisa a fazer, e que levou a um speedup de 2x, foi em vez de escrever cada string individualmente usar user-level buffering, o que é só um nome engraçado que se dá a quando o programa espera até ter uma certa quantidade de dados para os escrever para o file descriptor.
Havendo várias formas de o fazer, decidimos implementar um buffer circular, que é adequado em situações que queremos ter um comportamento FIFO. Num buffer circular temos uma região de memória reservada, de capacidade fixa, e vamos adicionando elementos (que podem ser de tamanho variável), sendo que os elementos mais recentes podem apagar os antigos (momento no qual se faz a escrita para o ficheiro).
Se tivermos um buffer vazio e inserirmos os elementos 1 2 3, o resultado é:
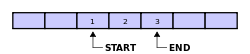
E se continuarmos e inserirmos 4 5 6 7 8 9 A B C ficamos com:
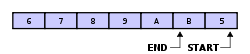
Sendo que fazemos o dump do conteúdo para o ficheiro antes de inserir o 8 que
substitui o 1. O objetivo de usar este tipo de escrita em batch é aumentar o
throughput, já que reduzimos o número total de operações de escrita, evitando ao máximo o overhead de cada chamada ao sistema. Outra micro-otimização que fizemos
foi usar uma região de memória para o buffer alocada contiguamente, ou seja,
em que os bytes estão seguidos na memória; se esta região tiver um tamanho que seja
múltiplo do tamanho das páginas do sistema que estamos a usar, isso permite que
haja DMA (direct memory access), o que permite ao hardware ler (e escrever) da
memória sem ter que recorrer ao CPU.
Depois de tudo isto: 38.5MB/s, o que dá cerca de 26s para o 1GB, yey!